Wie kann eine Machine Learning Pipeline mit einer graphischen Benutzeroberfläche in Ihrer
SAP Systemlandschaft erstellt und voll-integriert angewendet werden? In diesem Blog-Beitrag zeige ich Ihnen wie es geht.
Die Screenshots wurden im Rahmen eines Workshops bei der Swiss Data Science Conference 2020 mit SAP Data Intelligence Version 3.0 erstellt.
Als erster Use Case wurde die Preisvorhersage von Autos gewählt. Das entsprechende Datenset ist auf Kaggle zu finden, siehe https://www.kaggle.com/bozungu/ebay-used-car-sales-data. Der vorherzusagende Wert (output variable) ist der Preis in Euro für den ein Gebrauchtwagen in 2016 angeboten wurde. Die Daten sind in einer SAP HANA Datenbank gespeichert, wodurch ein In-Memory Zugriff und somit eine hohe Performance gewährleistet ist.
Das angewendete Vorgehensmodell basiert auf dem Cross Industry Standard Process for Data Mining (CRISP-DM) framework. Die ersten vier Phasen (Geschäftsverständnis, Datenverständnis, Modellierung und Evaluation) wurden zunächst mit der Unterstützung von Jupyter Notebook mit Python umgesetzt. Anschliessend wurde die Parameterkonfiguration des Gradient Boosting Regression Algorithmus mit dem kleinsten Root Mean Squared Error (RMSE) verwendet um die Machine Learning Pipeline in der graphischen Benutzeroberfläche von SAP Data Intelligence zu modellieren und im letzten Schritt als RESTful API zu deployen.
Data understanding in Python mit Jupyter Notebook
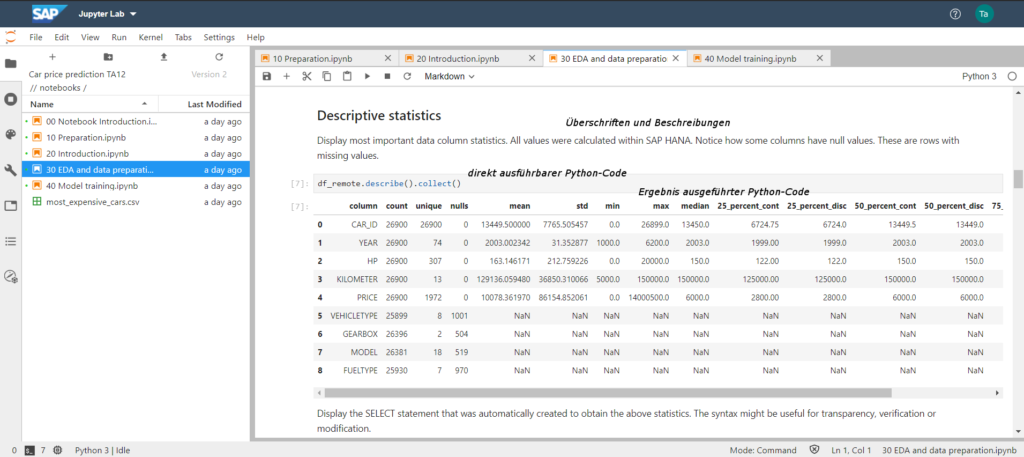
In der Phase des „Datenverständnis“ bietet die Verwendung von Jupyter Notebooks in der Programmiersprache Python eine Vielzahl von Funktionalitäten zur Analyse und der entsprechenden Aufbereitung der Ergebnisse. Im nachfolgenden Screenshot sind verschiedene Werte zu den Spalten in dem verwendeten Datenset zu finden, bspw. die Eindeutigkeit der Werte, Null-Werte sowie Durchschnitts- und Medianwerte. Damit ist bspw. möglich herauszufinden ob eine Ausreisser Behandlung notwendig ist und wie das Datenset sinnvoll in Training- und Validierungsdatenset aufgeteilt werden kann.
Model training and evaluation mit Hybrid Gradient Boosting Regression
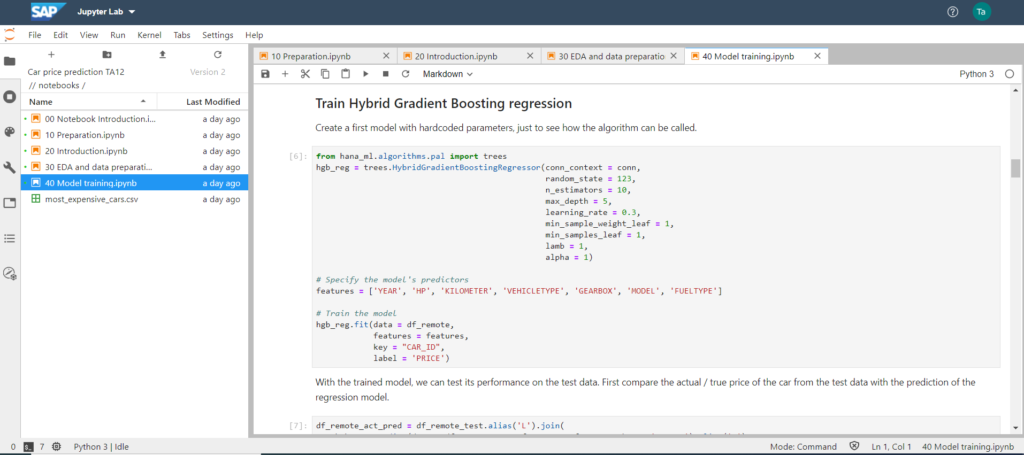
Nach dem Kennenlernen der Daten ist die Wahl des zu verwendenden Algorithmus auf das Hybrid Gradient Boosting Regression aus SAP Predictive Analytics Library (SAP PAL) gefallen. Die eingetragenen Parameter wurden als Start-Konfiguration gewählt, dann die zu verwendenden Spalten bzw. Features angegeben um im letzten Schritt eine Vielzahl von Trainingsmodellen zu erstellen. Für technische und mathematische Detailinformationen zum Gradient Boosting in Python kann ich folgende Webseite empfehlen: Gradient Boosting in Python from Scratch
Anschliessend besteht die Möglichkeit die Qualität der Modelle nach verschiedenen statistischen Kennzahlen zu bewerten. Im untenstehenden Screenshot wurde der Root-Mean-Square Error (RMSE) als Kennzahl gewählt. Die Parameter (N_ESTIMATORS und MAX_DEPTH) die zum kleinsten RSME geführt haben, wurden gewählt um das zu verwendende Modell zu trainieren.
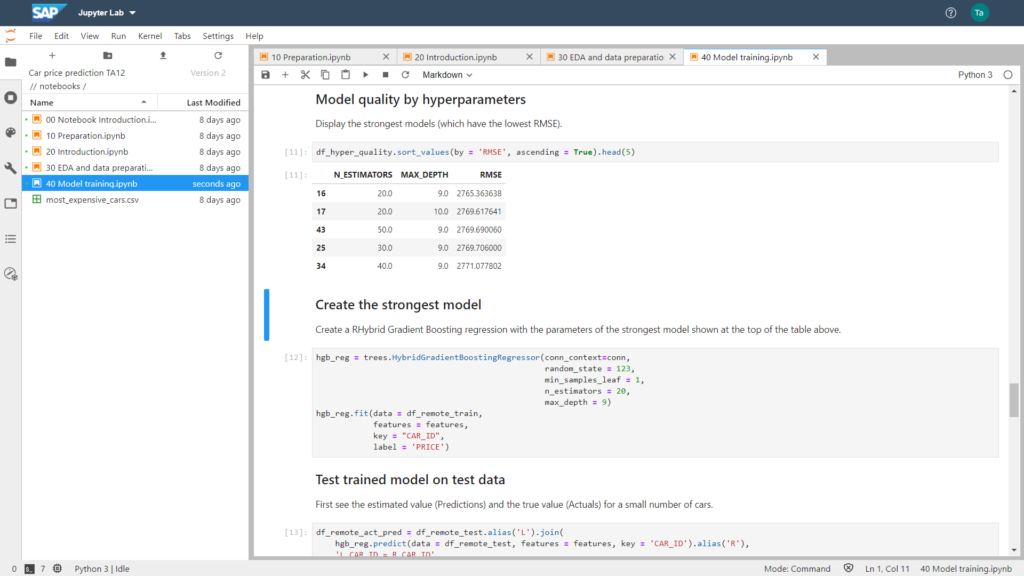
Verwendung Parameterkonfiguration im SAP Machine Learning Operator zur In-Memory Ausführung
Nach der Modellierung und Evaluation habe ich es in der Vergangenheit häufig erlebt, dass es für Unternehmen eine grosse Herausforderung ist, die entwickelten und evaluierten Modelle in Produktion zu deployen. Die Integration in die bestehenden Geschäftsprozesse sowie die Machine Learning Pipeline über verschiedene IT-Systeme (mit unterschiedlichen Programmiersprachen) zu steuern gehörten ebenfalls zu den teils unterschätzten Aktivitäten. Der Data Intelligence Modeler erlaubt diese Integration von IT-Systemen und Programmiersprachen in einer graphischen Benutzeroberfläche. Im nachfolgenden Screenshot ist die Data Pipeline ersichtlich, welche zum Training des stärksten Modells verwendet wird.
Da die Modellierung und Evaluation im CRSIP-DM häufig in mehreren Iterationen durchgeführt werden, ist sinnvoll und zugleich hilfreich dies in Jupyter Notebook durchzuführen. Anschliessend können der Standard-Komponente „HANA ML Training“ die Parameter, die zum stärksten Modell geführt haben, übergeben werden.
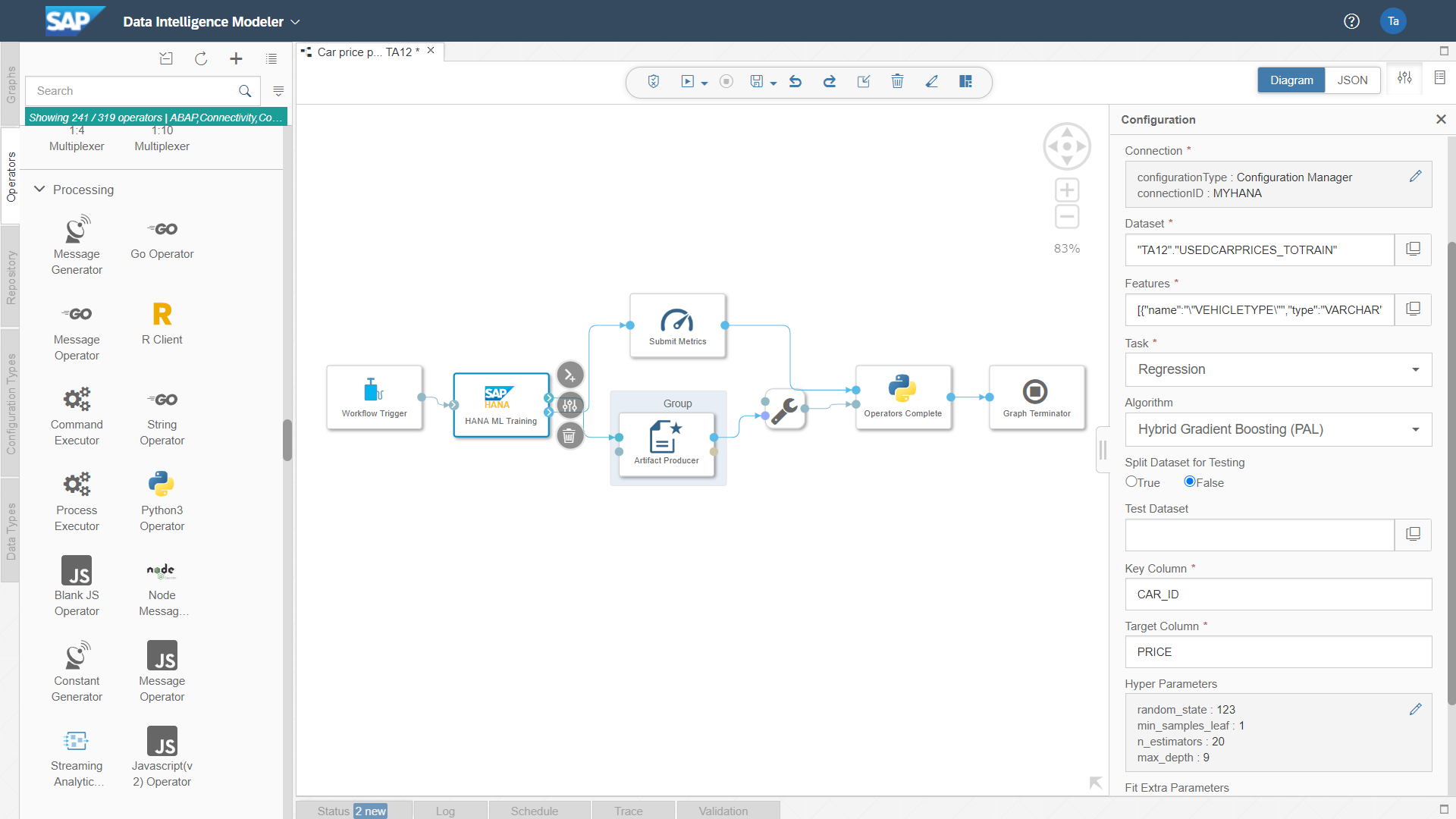
In jeder Pipeline im Data Intelligence Modeller können verschiedene Operatoren verwendet werden. Ein Beispiel ist das „HANA ML Training“. Es kann jedoch bspw. auch der Python Operator verwendet werden, um individuelle Python Code oder R Code zu integrieren (bspw. falls nicht ein Algorithmus aus der SAP PAL verwendet werden soll, wie in diesem Beispiel).
Der Zugriff auf eine Vielzahl von Datenbanken, Cloud Anbieter und weitere SAP Produkte wie S/4HANA ist ebenso möglich wie die Steuerung von SAP BW Prozessketten.
Deployment des Machine Learning Models via RESTful API
Nach der Erstellung des stärksten Modells kann dieses nun in einer Consumer-Pipeline via einem RESTful API zur Verfügung gestellt werden, wie im nachfolgenden Screenshot abgebildet.
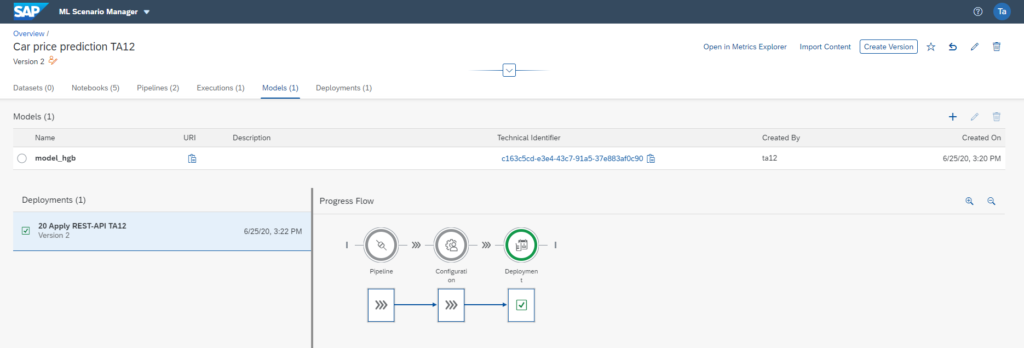
Aufruf RESTful API zur Preisvorhersage auf Basis des Machine Learning Modells
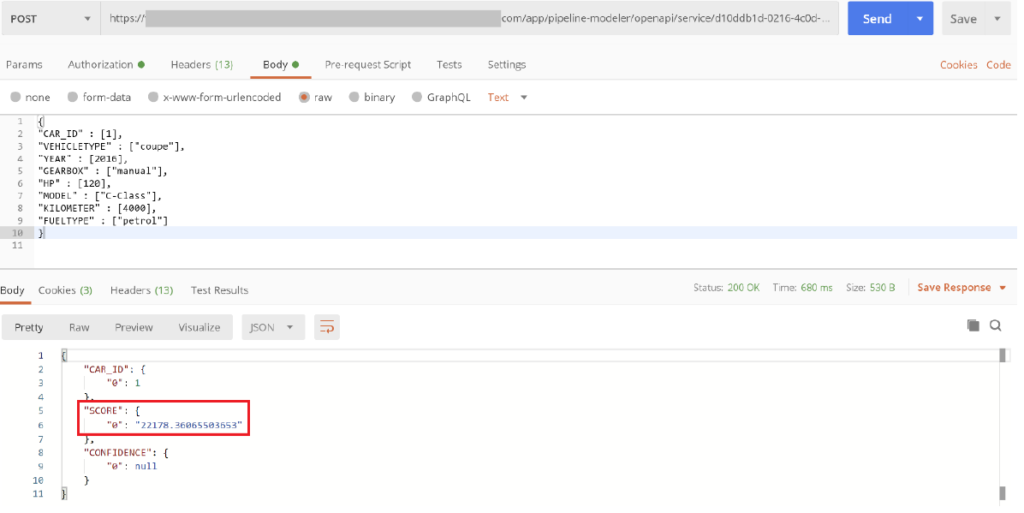
Nach erfolgreichen Deployment ist es möglich mit einem POST-Request die Schnittstelle zu benutzen, um sich für ein Auto den Preis vorhersagen zu lassen. Die Eigenschaften werden (wie im nachfolgenden Screenshot abgebildet) im JSON-Format im Body des POST-Request mitgegeben.
Integration von Machine Learning Pipelines in Ihre IT-Systemlandschaft
Wie kann eine Machine Learning Pipeline mit einer graphischen Benutzeroberfläche in Ihrer SAP Systemlandschaft erstellt und voll-integriert angewendet werden? In diesem Blog-Beitrag habe ich Ihnen gezeigt, wie dies mit SAP Data Intelligence möglich ist.
Des Weiteren ist es durch die Verwendung der Jupyter Notebooks mit Python einfach möglich die sehr iterative Vorgehensweise bei Data Mining oder Data Science Vorhaben integriert umzusetzen und einfach in bestehende Geschäftsprozesse und IT-Prozesse zu integrieren und dadurch einen Mehrwert zu bieten.
Gerne tausche ich und meinen Kollegen/innen mich mit Ihnen über Ihre Data Science Vorhaben aus und wir prüfen inwieweit wir Sie in Zukunft unterstützen können.
Vereinbaren Sie jetzt Ihren Expert Call. Wir freuen uns über Ihre Nachricht.