How can a machine learning pipeline with a graphical user interface be created in your
SAP system landscape and apply it in a fully integrated way? In this blog post, I will show you how.
The screenshots were taken during a workshop at the Swiss Data Science Conference 2020 using SAP Data Intelligence version 3.0.
The first use case chosen was the price prediction of cars. The corresponding data set can be found on Kaggle, see https://www.kaggle.com/bozungu/ebay-used-car-sales-data. The value to be predicted (output variable) is the price in Euros for which a used car was offered in 2016. The data is stored in an SAP HANA database, which ensures in-memory access and thus high performance.
The process model used is based on the Cross-Industry Standard Process for Data Mining (CRISP-DM) framework. The first four phases (business understanding, data understanding, modelling and evaluation) were first implemented with the support of Jupyter Notebook using Python. Subsequently, the parameter configuration of the gradient boosting regression algorithm with the smallest root means squared error (RMSE) was used to model the machine learning pipeline in the graphical user interface of SAP Data Intelligence and deployed as a RESTful API in the last step.
Data understanding in Python with Jupyter Notebook
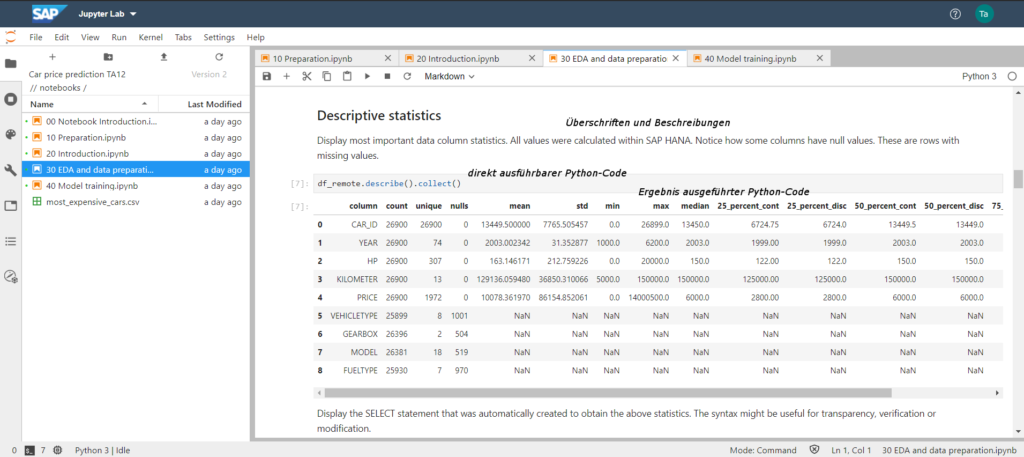
In the “data understanding” phase, the use of Jupyter Notebooks in the Python programming language offers a variety of functionalities for analysis and the corresponding preparation of the results. The following screenshot shows different values for the columns in the used dataset, e.g. the uniqueness of the values, zero values as well as average and median values. This makes it possible, for example, to find out whether an outlier treatment is necessary and how the data set can be sensibly divided into training and validation data sets.
Model Training and Evaluation with Hybrid Gradient Boosting Regression
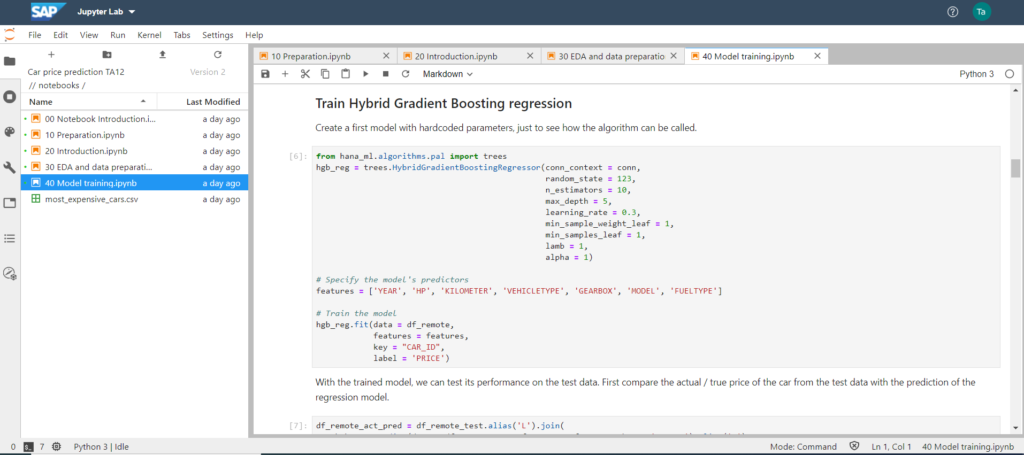
After getting to know the data, the choice of the algorithm to be used fell on the Hybrid Gradient Boosting Regression from SAP Predictive Analytics Library (SAP PAL). The parameters entered were chosen as the starting configuration, and then the columns or features to be used were specified in order to create a variety of training models in the last step. For technical and mathematical detailed information about Gradient Boosting in Python, I can recommend the following website: Gradient Boosting in Python from Scratch
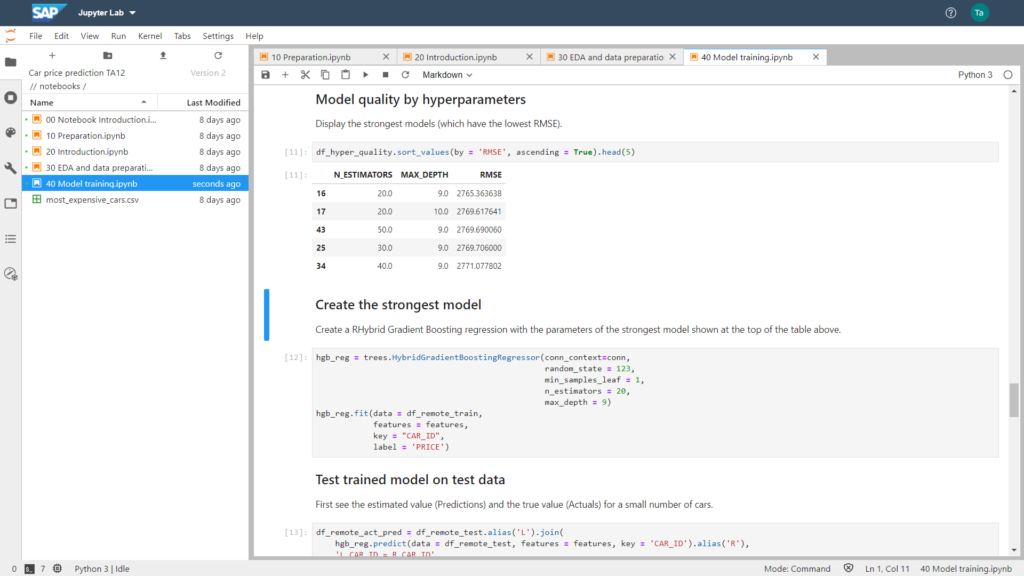
Subsequently, it is possible to evaluate the quality of the models according to various statistical key figures. In the screenshot below, the Root-Mean-Square Error (RMSE) was chosen as the metric. The parameters (N_ESTIMATORS and MAX_DEPTH) that led to the smallest RSME were chosen to train the model to be used.
Using Parameter Configuration in SAP Machine Learning Operator for In-Memory Execution
.
After modelling and evaluation, I have often experienced in the past that it is a big challenge for companies to deploy the developed and evaluated models into production. The integration into existing business processes as well as managing the machine learning pipeline across different IT systems (with different programming languages) were also among the sometimes underestimated activities. The Data Intelligence Modeler allows this integration of IT systems and programming languages in a graphical user interface. The screenshot below shows the data pipeline used to train the strongest model.
Since modelling and evaluation in CRSIP-DM are often done in several iterations, it makes sense and is helpful to do this in Jupyter Notebook. Afterwards, the parameters that led to the strongest model can be passed to the standard component “HANA ML Training”.
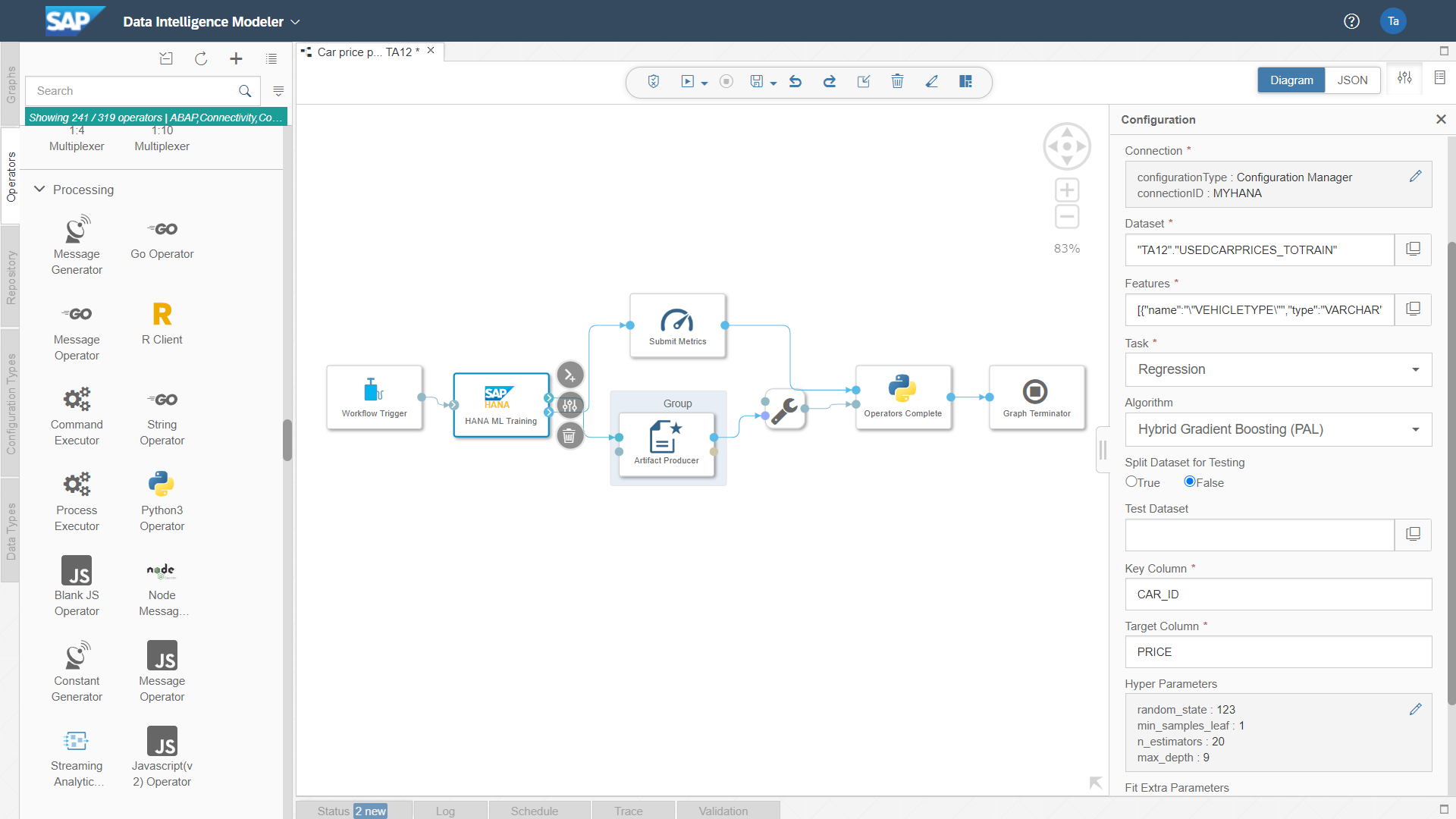
Different operators can be used in each pipeline in the Data Intelligence Modeller. An example is the “HANA ML Training”. However, the Python operator can also be used to integrate individual Python code or R code (e.g. if an algorithm from SAP PAL is not to be used, as in this example).
Access to a variety of databases, Cloud providers and other SAP products such as S/4HANA is possible as well as the control of SAP BW process chains.
Deployment of machine learning models via RESTful API
Once the strongest model has been created, it can now be made available in a consumer pipeline via a RESTful API, as shown in the screenshot below.
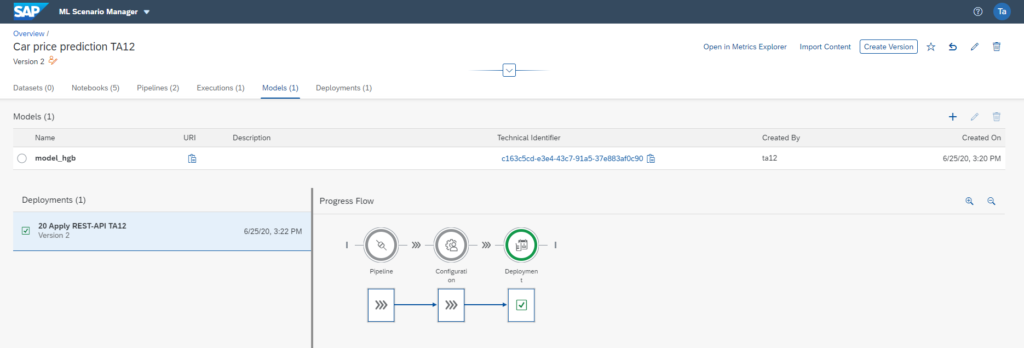
Call RESTful API for price prediction based on Machine Learning model.
After successful deployment, it is possible to use the interface with a POST request to get a price prediction for a car. The properties are provided in JSON format in the body of the POST request (as shown in the screenshot below).
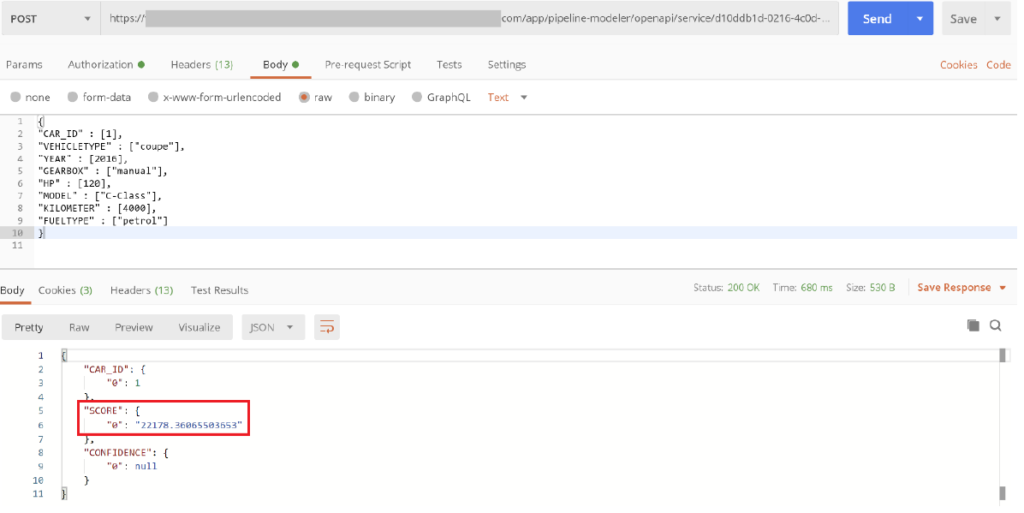
Integration of machine learning pipelines into your IT system landscape
How can a Machine Learning pipeline with a graphical user interface be created in your SAP system landscape and applied in a fully integrated way? I showed you how this is possible with SAP Data Intelligence in this blog post.
Furthermore, using Jupyter Notebooks with Python makes it easy to implement the very iterative approach to Data Mining or Data Science projects in an integrated way and easily integrate it into existing business processes and IT processes to provide added value.
My colleagues and I would be happy to discuss your data science projects with you and to check how we can support you in the future.
Arrange now your Expert Call. We are glad to hear from you.
