Been looking for it for a long time? Now you’ve found it!
Our overview of typical problems and solutions in the area of HANA SQLscript.
The solution patterns range from purely linguistic problems (e.g. “Which language element do I use to determine the first entry”) to formal problems (e.g. “How do I convert time characteristics in SQLscript”) and application-related requirements (e.g. “How do I look up master data in SQLscript”).
The sample solutions do not claim to be the sole or best solution to a problem but are intended to serve as a template and inspire you with different approaches. Your feedback on improvements, alternatives, and additions is always welcome!
The coding example is formulated as it might typically occur in an AMDP routine. However, this formulation cannot be used in a HANA Studio SQL window or in the SQL editor of the ABAP transaction DBACOCKPIT (as it is not defined there what the inTab should be). A coding example is therefore also given in some places, which could be used in the SQL window. These examples contain additional lines that build up the sample data.
Basic language elements:
- Initial values
- Temporary tables (table variables)
- Renaming columns
- Union of identical tables
- Joining two tables
- Case differentiation
- Defining, filling, and using variables
- Avoid NULL values
- Count the number of rows
- Conditions
- Sum, Max, Min, …
- Replace leading 0s
- Check for digits
- Condense spaces
- Remove invalid characters
- Determine the first data record
- Determine rank
- Access to the previous or subsequent line
Applicator solutions:
Initial values
Description
Initialize character-type columns with ”, numbers with 0.
Coding example
outtab =
SELECT
'' AS "/BIC/STRASSE",
0 AS "/BIC/HAUSNR"
FROM :intab; A similar formulation generates sample data that can then be used further.
Coding example SQL-Editor
SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY; Temporary tables (table variables)
Description
Tables are defined dynamically at runtime when they are filled with a select.
Note
Table variables do not have to be declared before use. However, the name must be preceded by a “:” in subsequent use.
Coding example
tmptab = SELECT * FROM :intab;
tmptab2 = SELECT * FROM :tmptab;
outtab = SELECT * from :tmptab2;
Table variables are an example of where SQL differs from SQLscript. These variables are part of the SQLscript language, but not of the SQL language.
In order to be able to use them in an SQL window, a so-called anonymous block must be inserted.
The last SELECT in the following example then generates the output of the result of the SQL window. Without this line, the statement is executed, but there is no result. Several such SELECTs at the end also generate several result windows in the SQL editor of the HANA Studio.
Coding example SQL window
DO
BEGIN
tmptab = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
tmptab2 = SELECT "SPALTE_A" FROM :tmptab;
SELECT * FROM :tmptab2; -- Tabelle als Resultat ausgeben
END; Renaming columns
Description
One or more columns are to be given a different name.
Coding example
outtab =
SELECT "ALTER_SPALTENNAME" AS "NEUER_SPALTENNAME" FROM :inTab; Coding example SQL window
DO
BEGIN
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
SELECT * FROM :tab1; -- Resultat Tabelle mit SPALTE_A
SELECT "SPALTE_A" AS "NEUE_SPALTE" FROM :tab1; -- Resultat umbenannt
END; Union of two structurally identical tables
Description
The union of two tables is formed. The tables must have an identical structure.
Coding example
outtab =
SELECT columns FROM :TAB1
UNION ALL
SELECT columns FROM :TAB2; Coding example SQL window
DO
BEGIN
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
tab2 = SELECT * FROM :tab1; -- 2. Tabelle mit Daten
tab3 = SELECT * FROM :tab1
UNION ALL
SELECT * FROM :tab2;
SELECT * FROM :tab3; -- Resultat ausgeben
END; Join two tables
Description
The join of two tables is formed.
Coding example
outtab =
SELECT T1.*, T2.* FROM :TAB1 AS T1
LEFT OUTER JOIN :TAB2 AS T2
ON T1.SPALTE_A = T2.SPALTE_X AND
T1.SPALTE_B = T2.SPALTE_Y;
Coding example SQL window
DO
BEGIN
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
tab2 = SELECT 'A' AS "SPALTE_X",
'C' AS "SPALTE_Y",
2 AS "MENGE"
FROM DUMMY;
tab3 = SELECT T1.*, T2.* from :tab1 AS T1
LEFT OUTER JOIN :tab2 AS T2
ON T1."SPALTE_A" = T2."SPALTE_X";
SELECT * FROM :tab3; -- Resultat ausgeben
END; Case distinction
Description
You can already make a case distinction in the SELECT statement in the column to be determined with the help of CASE.
Coding example
outtab =
SELECT
CASE BUCHUNGSART
WHEN 'HABEN' THEN BETRAG
WHEN 'SOLL' THEN -1 * BETRAG
ELSE 0
END AS BETRAG_VZ
FROM :intab; This statement is equivalent to the following version:
outtab =
SELECT
CASE
WHEN BUCHUNGSART = 'HABEN' THEN BETRAG
WHEN BUCHUNGSART = 'SOLL' THEN -1 * BETRAG
ELSE 0
END AS BETRAG_VZ
FROM :intab; In the 2nd formulation, you have more freedom to formulate more complex conditions in the WHEN condition, e.g:
outtab =
SELECT
CASE
WHEN BUCHUNGSART = 'HABEN' AND
NOT ( STORNOFLAG = 'X' )
THEN BETRAG
WHEN BUCHUNGSART = 'HABEN' AND
STORNOFLAG = 'X'
THEN 0
WHEN BUCHUNGSART = 'SOLL' THEN -1 * BETRAG
ELSE 0
END AS BETRAG_VZ
FROM :intab; Coding example SQL window
DO
BEGIN
tab1 = SELECT 'HABEN' AS "BUCHUNGSART", 1.5 AS "BETRAG" FROM DUMMY
UNION ALL
SELECT 'SOLL' AS "BUCHUNGSART", 2.5 AS "BETRAG" FROM DUMMY;
tab2 = SELECT "BUCHUNGSART", "BETRAG",
CASE
WHEN "BUCHUNGSART" = 'HABEN' THEN "BETRAG"
WHEN "BUCHUNGSART" = 'SOLL' THEN -1 * "BETRAG"
ELSE 0
END AS "BETRAG_VZ"
FROM :tab1;
SELECT * FROM :tab2; -- Resultat ausgeben
END; Define, fill and use variables
Description
You can define local variables. These can be filled with SELECT statements, but their content can also be read out again using SELECT or they can be used in CASE statements.
Coding example
DECLARE lv_tvarvc STRING;
SELECT DISTINCT LOW INTO lv_tvarvc
FROM "TVARVC"
WHERE "NAME" = 'my_setting';
outtab =
SELECT :lv_tvarvc AS TVARVC, * FROM intab; Coding example SQL window
DO
BEGIN
DECLARE lv_tvarvc STRING;
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY;
SELECT 'Value1' INTO lv_tvarvc FROM DUMMY;
SELECT :lv_tvarvc, * FROM :tab1; -- Resultat ausgeben
END; Avoid NULL values
Description
If, for example, no matching hits are found in a left outer join in the joined table, the selected columns of this table contain NULL values as a result. These values are quite unpleasant, e.g. because they do not correspond to an initial value in ABAP. Therefore, such NULL values should always be intercepted with the COALESCE function. COALESCE(A,B) returns the value A if A is not NULL, otherwise B. This means that you can always use B to specify a substitute value to be returned instead of NULL.
Alternatively, you can also work with the IFNULL function.
Note
A coding example can be found in the section Date calculation.
Count number of lines
Description
You can use the COUNT operator to count the rows. However, you can also determine how often characteristics occur in each case, e.g. whether only once or several times.
Here we only give an example for the SQL console, the syntax is then easily transferable to use cases in AMDP.
Coding example SQL window
DO
BEGIN
DECLARE lv_anz_zeilen INT;
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY
UNION
SELECT 'A' AS "SPALTE_A",
'C' AS "SPALTE_B",
2.5 AS "BETRAG"
FROM DUMMY;
SELECT COUNT( * ) INTO lv_anz_zeilen FROM :tab1; -- Gesamtzahl als
-- lokale Variable
tab2 = SELECT COUNT ( * ) AS "COUNTER" FROM :tab1; -- Gesamtzahl als Tabelle
SELECT :lv_anz_zeilen AS "Gesamtzahl",
COUNT(*) AS "Anzahl pro Merkmal SPALTE_A",
"SPALTE_A" FROM :tab1
GROUP BY "SPALTE_A"; -- Ausgabe 1, auch wieviele Ausprägungen SPALTE_A
SELECT * from :tab2; -- Ausgabe 2
END; Conditions
Description
Conditions can be formulated with the help of IF.
Note
Surprisingly often, IF statements can be replaced by CASE statements in SELECT. These are better suited to processing the data en masse. IF is often used to look at individual cases, which should be avoided in order to achieve good performance.
Coding example
DO
BEGIN
DECLARE lv_anz_zeilen INT;
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY
UNION
SELECT 'A' AS "SPALTE_A",
'C' AS "SPALTE_B",
2.5 AS "BETRAG"
FROM DUMMY;
SELECT COUNT( * ) INTO lv_anz_zeilen FROM :tab1; -- Gesamtzahl
IF :lv_anz_zeilen > 0 THEN
SELECT 'Tabelle ist nicht leer' AS "TEXT" from DUMMY;
ELSE
SELECT 'Tabelle ist leer' AS "TEXT" from DUMMY;
END IF;
END; Sum, Max, Min, ...
Description
Aggregations such as summation, maximum of a column, etc. can again be created directly in the SELECT statement.
Note
The columns over which the aggregate function is formed must be in a GROUP-BY clause. In general, these are all columns except those on which the sum, maximum, or similar is to be formed.
Coding example
DO
BEGIN
tab1 = SELECT 'A' AS "SPALTE_A",
'B' AS "SPALTE_B",
1.5 AS "BETRAG"
FROM DUMMY
UNION
SELECT 'A' AS "SPALTE_A",
'C' AS "SPALTE_B",
2.5 AS "BETRAG"
FROM DUMMY;
SELECT "SPALTE_A", MAX( "BETRAG" ) AS MAX FROM :tab1
GROUP BY "SPALTE_A"; -- Max pro Ausprägung SPALTE_A
SELECT "SPALTE_B", MAX( "BETRAG" ) AS MAX FROM :tab1
GROUP BY "SPALTE_B"; -- Max pro Ausprägung SPALTE_B
END; Replace leading 0s
Description
Leading 0s can be replaced using the LTRIM operator.
Note
The LTRIM operator can also be used to eliminate leading spaces, for example.
Coding example
SELECT LTRIM( BPARTNER, '0') AS BP FROM :intab; Coding example SQL window
SELECT LTRIM( '00001234', '0') AS BP FROM DUMMY; Check for digits
Description
You can check columns to see whether they only contain digits (e.g. date fields in internal ABAP format).
Note
In the example, the data records that contain something that is not a digit are selected and marked.
Coding example
SELECT DATUM, 'X' AS MARKIERUNG FROM :intab
WHERE DATUM LIKE_REGEXPR '[^0-9]'; Condensing spaces
Description
You can remove leading, trailing, and center spaces by using the very powerful REPLACE_REGEX operator.
Coding example
SELECT REPLACE_REGEXPR ('[\s]' in 'ABC DEF') FROM DUMMY; Remove invalid characters
Description
You can remove characters that are invalid for BW by using the very powerful REPLACE_REGEX operator in combination with an expression that removes all non-printable characters from a text.
The first coding variant removes all non-printable characters, which unfortunately also include German umlauts, for example. If this is not desired, the second variant only removes certain invisible control characters plus the character for protected spaces (Hex A0).
Coding example
SELECT REPLACE_REGEXPR( '([^[:print:]])' IN 'TEXT' WITH '' OCCURRENCE ALL ) FROM DUMMY;
SELECT REPLACE_REGEXPR( '([[:cntrl:]\x{00A0}])' IN 'TEXT' WITH '' OCCURRENCE ALL ) FROM DUMMY; Determine first data set
Description
MAX or MIN functions can be used to determine the newest or oldest data. However, you can also determine the first data record of a certain series, e.g. the BusinessPartner with the earliest change date.
Note
Similarly, you can of course also determine the last data record with LAST_VALUE.
Coding example
SELECT FIRST_VALUE( BPARTNER ORDER BY CHANGED_ON ) FROM :intab;
SELECT BPARTNER, LAST_VALUE ( AMOUNT ORDER BY CHANGED_ON ) AS AMOUNT FROM :intab
GROUP BY BPARTNER; Determine rank
Description
You can use the RANK function to assign a rank number to data. This is a type of sort number but has the advantage that the data does not have to be sorted or re-sorted.
Note
This can be used, for example, to determine the last position for a document.
Coding example
tab1 = SELECT *,
RANK() OVER ( PARTITION BY intab."BELEGNUMMER" ORDER BY intab."POSITION" DESC )
AS ZEILENNUMMER_ABSTEIGEND
FROM :intab;
tab2 = select * from :tab1
where ZEILENNUMMER_ABSTEIGEND = 1; Access to previous or subsequent lines
Description
If you want to compare rows in a table with the previous or subsequent row, this often leads to a cursor being opened and a loop being programmed. This is possible in principle, but it contradicts the paradigm of processing the data as massively as possible in order to achieve optimum performance.
One possibility would be to join the table with itself offset by one row, which would allow a comparison within one (then twice as wide) row.
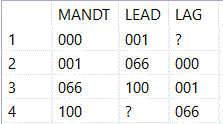
However, HANA SQLscript offers a way to access the corresponding rows with the LEAD and LAG functions.
Note
The example lists the clients of a system. The first column contains the normal list, the second column uses Lead to access the next row in the table and Lag to access the previous row.
Coding example
select MANDT,
LEAD( MANDT ) OVER ( ORDER BY MANDT ) AS LEAD,
LAG( MANDT ) OVER ( ORDER BY MANDT ) AS LAG
FROM T000;
Outcome
Date calculation
Description
The other characteristics (week, month, year,…) are to be derived from the calendar day.
Note
In HANA, the timetables must be filled once (→ Modeler perspective), otherwise the tables are empty.
Alternatively, the tables can also be updated with MDX commands such as
MDX UPDATE TIME DIMENSION … or MDX UPDATE FISCAL CALENDAR …
can be used. Pay attention to what the finest granularity should be (e.g. day or second).
If nothing is found, the system falls back to 01.01.2020 (this was a Wednesday, weekday = 3, hence this value).
Coding example
-- UDATE bitte durch das entsprechende Zeitmerkmal ersetzen
SELECT
COALESCE( I.UDATE, '20200101' ) AS CALDAY,
COALESCE( TO_NVARCHAR( T.DAY_OF_WEEK_INT + 1 ), '3' ) AS WEEKDAY1,
COALESCE( T.CALMONTH, '01' ) AS CALMONTH,
COALESCE( T.CALWEEK, '202001' ) AS CALWEEK,
COALESCE( T.MONTH, '01' ) AS CALMONTH2,
COALESCE( T.CALQUARTER, '20201' ) AS CALQUARTER,
COALESCE( TO_NVARCHAR( T.QUARTER_INT ), '1' ) AS CALQUART1,
CASE
WHEN COALESCE( T.QUARTER_INT, 1 ) = 1 OR
COALESCE( T.QUARTER_INT, 1 ) = 2 THEN
'1'
ELSE
'2'
END AS HALFYEAR1,
COALESCE( T.YEAR, '2020' ) AS CALYEAR,
FROM :intab AS I
LEFT OUTER JOIN "_SYS_BI"."M_TIME_DIMENSION" AS T
ON I.UDATE = T.DATE_SAP; Derivation of a current UTC timestamp
Description
The current UTC timestamp is to be determined in an AMDP routine.
Note
Example coding for an AMDP field procedure.
Coding example
METHOD PROCEDURE BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT OPTIONS READ-ONLY.
outtab =
SELECT to_nvarchar(current_utctimestamp, 'YYYYMMDDHH24MISS') AS "ETL_TIMESTAMP",
record,
sql__procedure__source__record
FROM :intab;
errortab =
SELECT '' AS "ERROR_TEXT" ,
'' AS "SQL__PROCEDURE__SOURCE__RECORD"
FROM dummy
WHERE 0 = 1;
ENDMETHOD. Derivation of the Request TSN
Description
In BW on HANA, the AMDP interface does not provide the request number. It has to be derived somewhat laboriously in order to be able to store this number in a corporate memory, for example (recommended, as you want to reload individual requests and this field is not available as a selection in the DTP in the standard system).
Note
Example AMDP field routine.
The target ADSO must be specified in the coding.
Coding example
METHOD PROCEDURE BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT
OPTIONS READ-ONLY using RSPMREQUEST.
declare lv_reqtsn varchar(23);
SELECT request_tsn INTO lv_reqtsn FROM rspmrequest
where datatarget = '' AND
request_status = 'Y' AND
last_operation_type = 'C' AND
request_is_in_process = 'Y' AND
storage = 'AQ';
outtab =
SELECT lv_reqtsn AS "ETL_REQTSN",
record,
sql__procedure__source__record
FROM :inTab as input;
errortab =
SELECT '' AS "ERROR_TEXT" ,
'' AS "SQL__PROCEDURE__SOURCE__RECORD"
FROM dummy
WHERE 0 = 1;
ENDMETHOD. Latest data from a wo-ADSO
Description
When you read data from a write-optimized ADSO (wo-ADSO), it is often necessary to read the latest status of this data, i.e. the latest request. This is easily done by searching for the maximum request number.
Coding example
SELECT T1.REQTSN, T1.KEY, T1.FIELD
FROM WO-ADSO as T1
JOIN ( SELECT MAX(REQTSN) as TSN, KEY FROM WO-ADSO GROUP BY KEY ) AS T2
ON T1.REQTSN = T2.TSN AND
T1.KEY = T2.KEY
WHERE T1.KEY = ...;
Reading master data
Description
You can read the master data of an InfoObject by adding the P table (for time-dependent master data, the Q table) of the InfoObject.
Note
If referential integrity is given (i.e. master data is guaranteed to exist for the transaction data), then an INNER JOIN can be used. This is more efficient than an OUTER JOIN.
Otherwise, a LEFT OUTER JOIN should be used and any occurrence of NULL values should be intercepted by COALESCE.
Coding example
SELECT T1.*,
COALESECE( T2.FIELD, '') AS FIELD
FROM ADSO as T1
LEFT OUTER JOIN /BIC/POBJECT AS T2
ON T2.KEY = T1.OBJECTFIELD
WHERE T2.OBJVERS = 'A' AND ...;
Catch SQL errors in AMDP
Description
If SQL errors occur in the AMDP, these can be intercepted and returned to the DTP as error messages.
Note
The following code should then be placed at the beginning of the AMDP script.
Coding example
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
outtab = SELECT TOP 0 * from :outtab;
errortab = SELECT 'My Error Message' AS ERROR_TEXT,
'' AS SQL__PROCEDURE__SOURCE__RECORD FROM DUMMY';
END;
Throw own SQL error messages in AMDP
Description
You can also throw your own error messages, which then appear both in the log of the DTP and as SQL error messages in the trace files of the index server of the HANA DB.
Note
The following code should then be placed at the beginning of the AMDP script.
Coding example
DECLARE MYCOND CONDITION FOR SQL_ERROR_CODE 10001;
DECLARE EXIT HANDLER FOR MYCOND RESIGNAL;
SIGNAL MYCOND SET MESSAGE_TEXT = ' Typical Not-found Error';
-- in case of error throw here
SIGNAL MYCOND;
Post valid records in AMDP, write incorrect ones to error stack
Description
If you are in a BW/4HANA release, the setting “Allow error handling for HANA routines” must be set in the transformation as a prerequisite. If this is set, the AMDP interface defines an errorTab table in addition to the outTab table.
A suitable setting must also be made in the DTP, e.g. the setting “Set request to green, write error stack, update valid records”.
Note
The following code shows an example of how records are read from a master data table. Those records for which a non-empty entry is found are treated as valid records, the others are treated as incorrect records.
Coding example
table1 = SELECT
:i_req_requid as ZTS1REQTSN,
CALYEAR,
COUNTRY,
PRODUCT,
I.RECORDMODE,
I."/BIC/ZTS1CNTRY",
COALESCE(P."/BIC/ZTS1FAREA",'') AS "/BIC/ZTS1FAREA",
to_nvarchar(current_utctimestamp, 'YYYYMMDDHH24MISS') AS UTC,
QUANTITY,
RECORD,
SQL__PROCEDURE__SOURCE__RECORD
FROM :inTab as I
LEFT OUTER JOIN "/BIC/PZTS1CNTRY" AS P
ON I."/BIC/ZTS1CNTRY" = P."/BIC/ZTS1CNTRY" AND
P.OBJVERS = 'A' AND
NOT ( P.RECORDMODE = 'R' );
-- Allow Error Handling for HANA Routines is enabled
if :i_error_handling = 'TRUE' then
errorTab = select
'FAREAMISSING' as ERROR_TEXT,
SQL__PROCEDURE__SOURCE__RECORD as SQL__PROCEDURE__SOURCE__RECORD
FROM :table1
where "/BIC/ZTS1FAREA" = '';
end if;
outTab = select * from :table1
where NOT ( "/BIC/ZTS1FAREA" = '' );
