In the two previous parts of this blog, I described how the Fischertechnik factory simulation generates data in the form of a CSV file and how this data gets into the Hadoop cluster and is even available there as a table. This part is now about the various ways in which the contents of this table can now be reported on.
There are two relatively simple ways in which the data in this Hadoop table can be made available to SAP tools:
1. in a HANA database via SDA (Smart Data Access) or SDI (Smart Data Integration). The data can then be consumed, for example, in an SAP Analytics for Cloud (no SAP BW system is then required for this) or in an SAP BW system.
2. with the help of the middleware GLUE from our partner company Datavard, it is very easy to use ABAP transactions to create tables in Hadoop, read them out or move content back and forth between tables located in Hadoop and ABAP tables. This does not necessarily require a HANA database, but it does require an ABAP application server. I would like to present both possibilities here.
SDA/SDI
SDA/SDI SDA or SDI are connector libraries delivered by SAP. They allow the connection of a remote database and generate virtual links to the tables of this remote database. These virtual links can then be accessed as if they were local tables in the HANA database. The SDI adapters are technologically more advanced and have additional capabilities compared to the SDA adapters. In some cases, for example, they are capable of extracting only the delta changes by evaluating the changelogs rather than the tables. Whether and which capabilities the adapters have has to be checked in each individual case, e.g. in the Hadoop case, the adapters do not have this delta capability. Furthermore, in contrast to SDA, the SDI adapters are additionally chargeable.
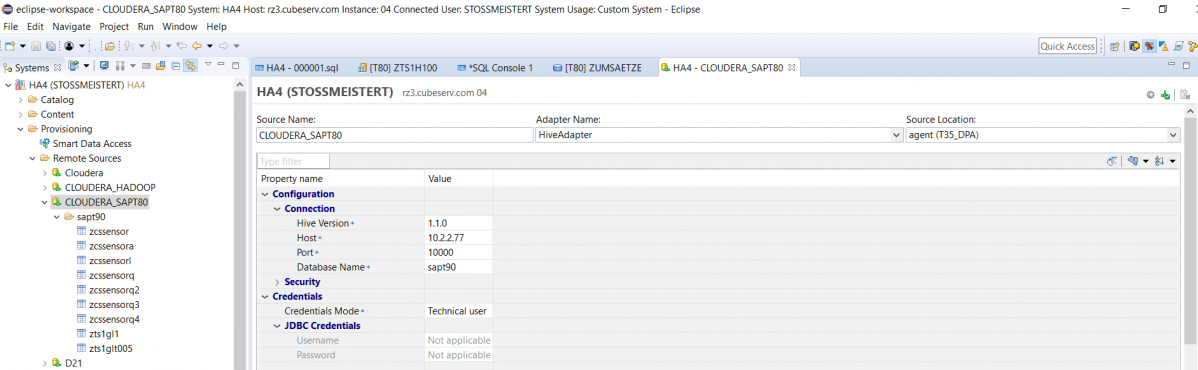
We even connected our HANA database (HA4) with two different SDI adapters for test purposes, once via the SDI Hive adapter:
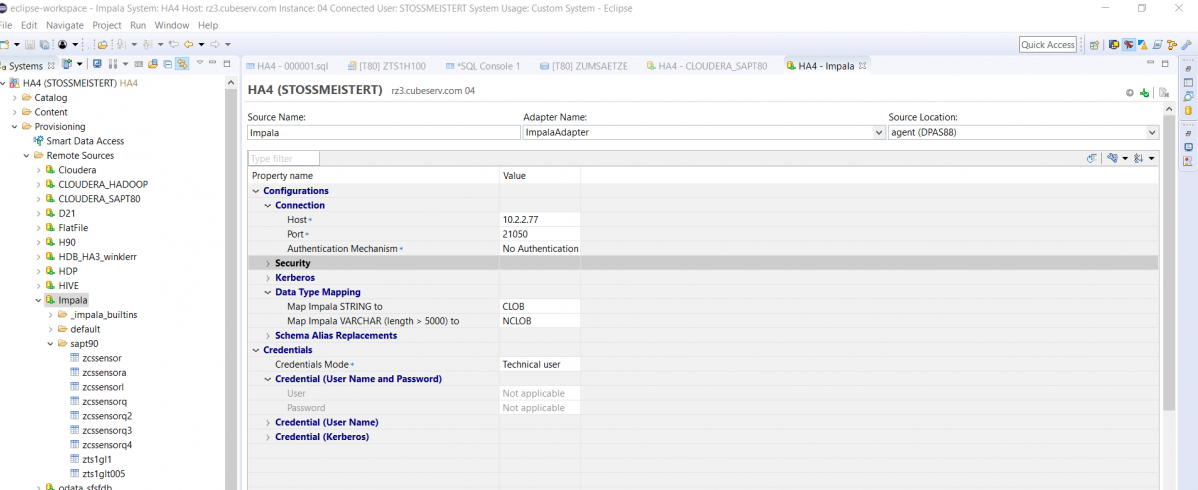
and once via the SDI-ImpalaAdapter:
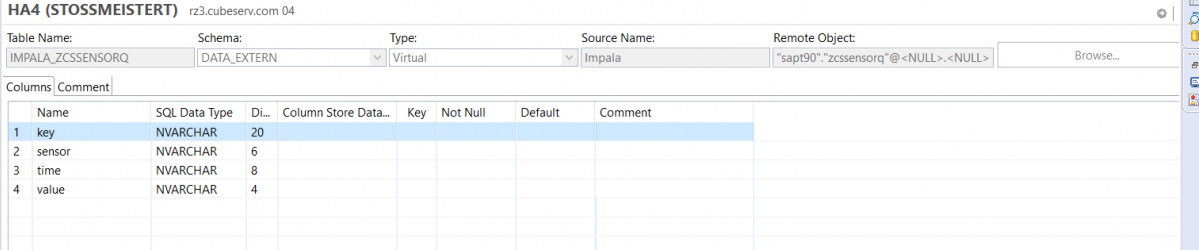
This makes it easy to create virtual table links (here in the DATA_EXTERN schema), which can be used to access the original table.
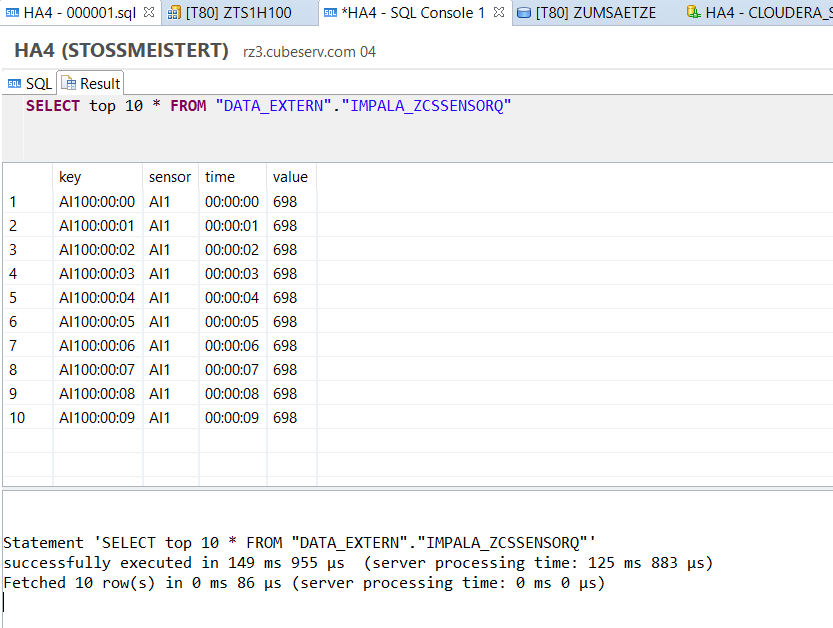
This works also quite wonderfully, as e.g. the following query shows: