Predviđanje cijene automobila odabrano je kao prvi Use Case. Odgovarajući skup podataka može se naći na Kaggleu, pod: https://www.kaggle.com/code/bozungu/ebay-used-car-sales-data/notebook.
Vrijednost koju treba predvidjeti (output variable) je cijena u eurima za koju je ponuđen polovni automobil 2016. godine. Podaci se pohranjuju u SAP HANA bazu podataka, što osigurava pristup u memoriji i time visoke performanse. Korišteni model procesa je baziran na međunarodnom standardnom procesu za rudarenje podataka (CRISP-DM) okviru. Prve četiri faze (razumijevanje poslovanja, razumijevanje podataka, modeliranje i evaluacija) su inicijalno implementirane pomoću Pythona uz podršku Jupyter Notebook-a. Zatim je konfiguracija parametara algoritma regresije za povećanje gradijenta s najmanjom srednjom kvadratnom greškom (RMSE) korištena za modeliranje cjevovoda strojnog učenja u grafičkom korisničkom sučelju SAP Data Intelligence i u posljednjem koraku za njegovu implementaciju kao RESTful API.
Data understanding u Python-u sa Jupyter Notebook-om
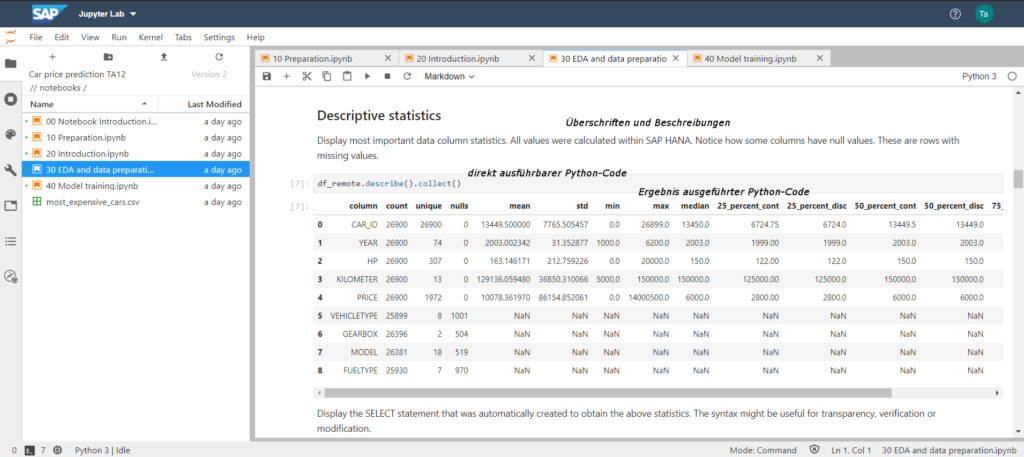
U fazi “razumijevanja podataka”, upotreba Jupyter Notebook-a u programskom jeziku Python nudi niz funkcionalnosti za analizu i odgovarajuću obradu rezultata. Na slici ispod možete pronaći različite vrijednosti za stupce u korištenom skupu podataka, npr. jedinstvenost vrijednosti, nulte vrijednosti kao i prosječne i srednje vrijednosti. Ovo omogućava, na primjer, da se sazna da li je neophodan tretman vanrednog stanja i kako se skup podataka može podijeliti na skupove podataka za obuku i validaciju.
Model training and evaluation sa Hybrid Gradient Boosting Regression
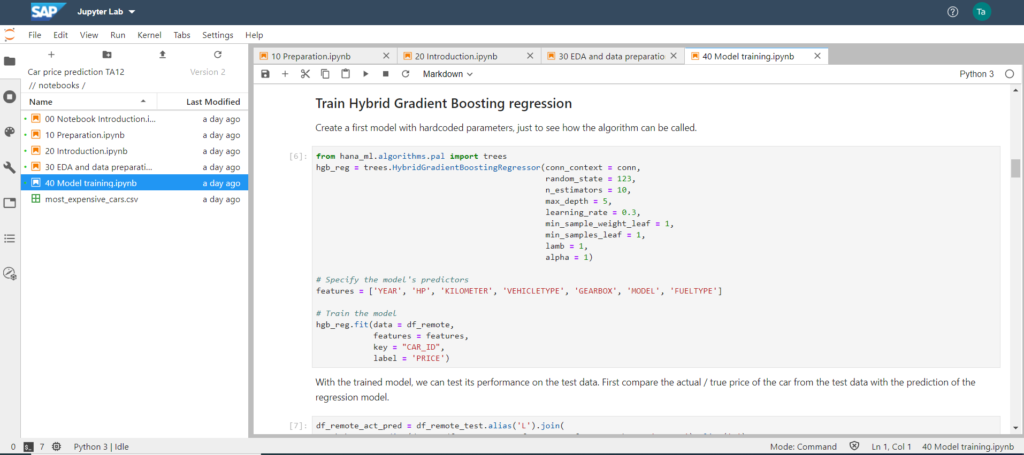
Nakon upoznavanja podataka, izbor algoritma koji će se koristiti pao je na Hybrid Gradient Boosting Regression iz SAP Predictive Analytics Library (SAP PAL). Uneseni parametri su odabrani kao početna konfiguracija, zatim su specificirani stupci ili karakteristike koje će se koristiti kako bi se kreirao veliki broj modela obuke u posljednjem koraku. Za detaljne tehničke i matematičke informacije o podizanju gradijenta u Pythonu, mogu preporučiti sljedeću web stranicu:
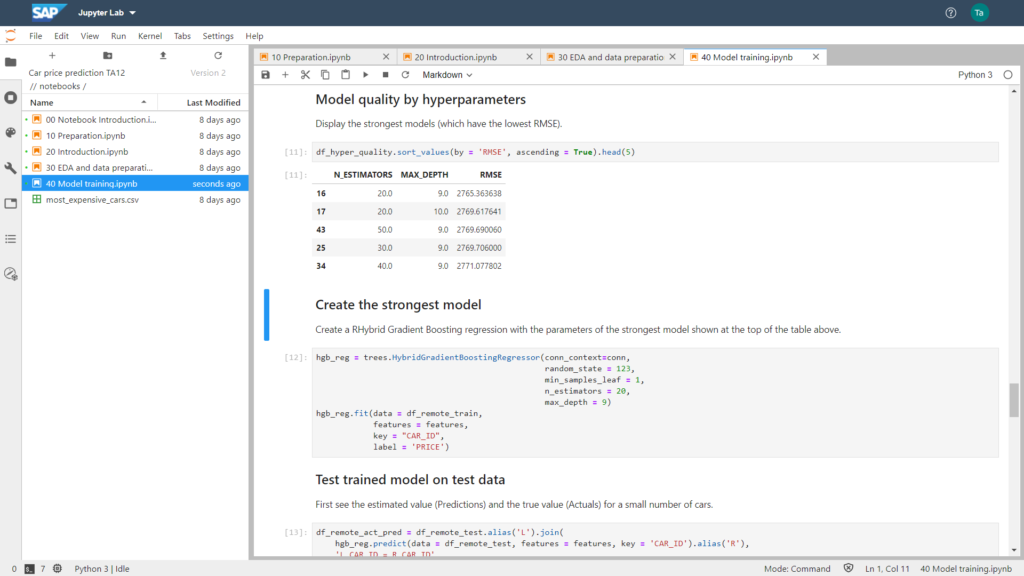
Zatim postoji mogućnost evaluacije kvaliteta modela prema različitim statističkim pokazateljima. Na snimku ekrana ispod, kao metrika je odabrana srednja kvadratna greška (RMSE). Parametri (N_ESTIMATORS i MAX_DEPTH) koji su doveli do najmanjeg RSME odabrani su za obuku modela koji će se koristiti.
Korištenje parametara konfiguracije u SAP Machine Learning Operator-u za In-Memory izvedbu
Nakon modeliranja i evaluacije, često sam u prošlosti vidio da je veliki izazov za tvrtke implementirati razvijene i evaluirane modele u proizvodnju. Integracija u postojeće poslovne procese i cjevovod strojnog učenja putem različitih IT sustava (s različitim programskim jezicima) također su među podcijenjenim aktivnostima. Data Intelligence Modeler omogućuje ovu integraciju IT sustava i programskih jezika u grafičko korisničko sučelje. Snimka zaslona u nastavku prikazuje podatkovni cjevovod koji se koristi za treniranje najjačeg modela.
Budući da se modeliranje i evaluacija u CRSIP-DM često provode u nekoliko iteracija, ima smisla i korisno je to učiniti u Jupyter Notebook-u. Parametri koji su doveli do najjačeg modela mogu se zatim prenijeti u standardnu komponentu “HANA ML Training”.
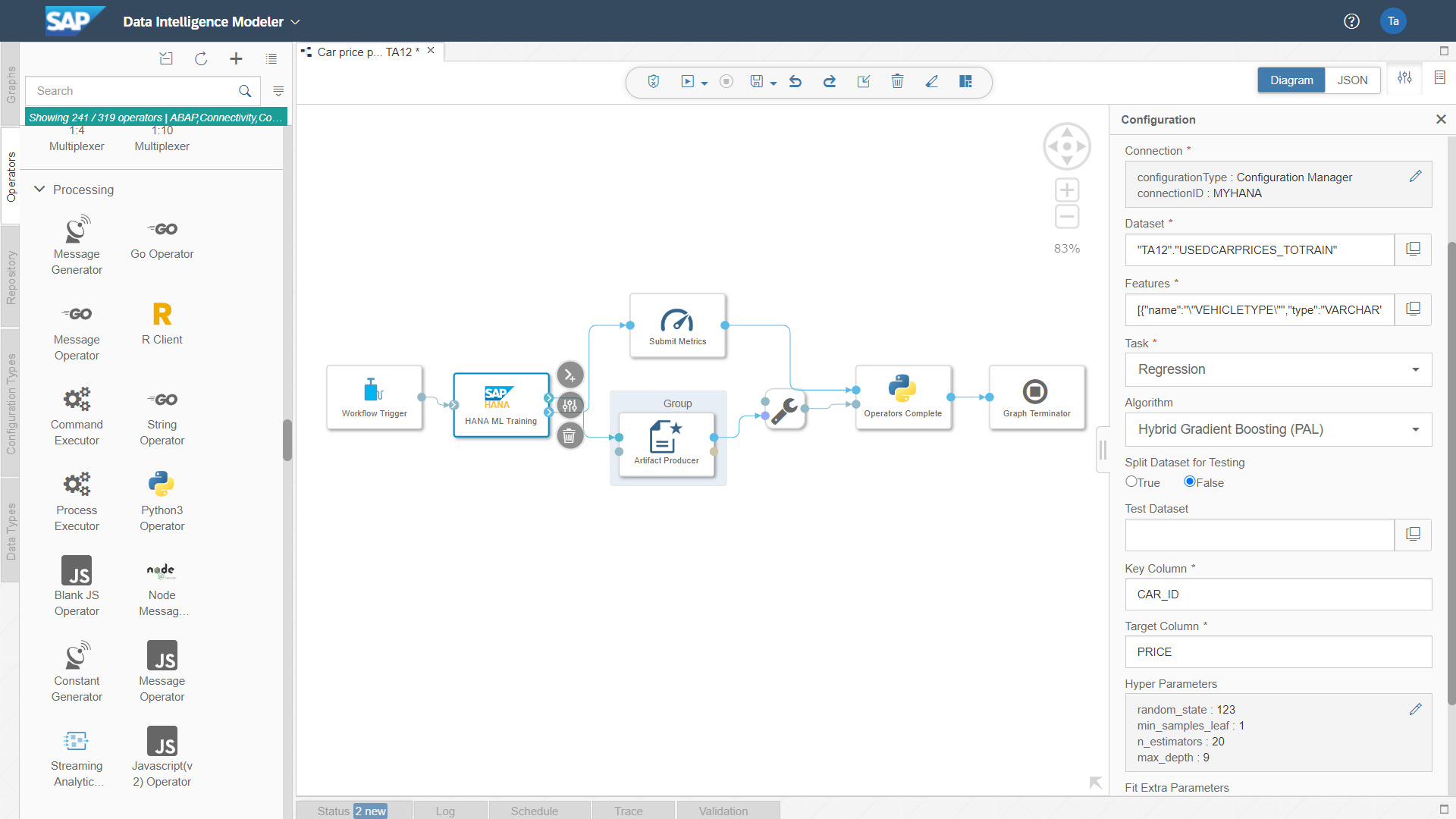
U svakom cjevovodu u Data Intelligence Modeller-u mogu se koristiti različiti operatori. Primjer je “HANA ML Training”. Međutim, Python operator također se može koristiti, na primjer, za integraciju pojedinačnog Python koda ili R koda (npr. ako se ne koristi algoritam iz SAP PAL-a, kao u ovom primjeru).
Pristup velikom broju baza podataka, cloud providera i drugih SAP proizvoda kao što je S/4HANA jednako je moguć kao i kontrola SAP BW procesnih lanaca.
Deployment Machine Learning Model-a preko RESTful API
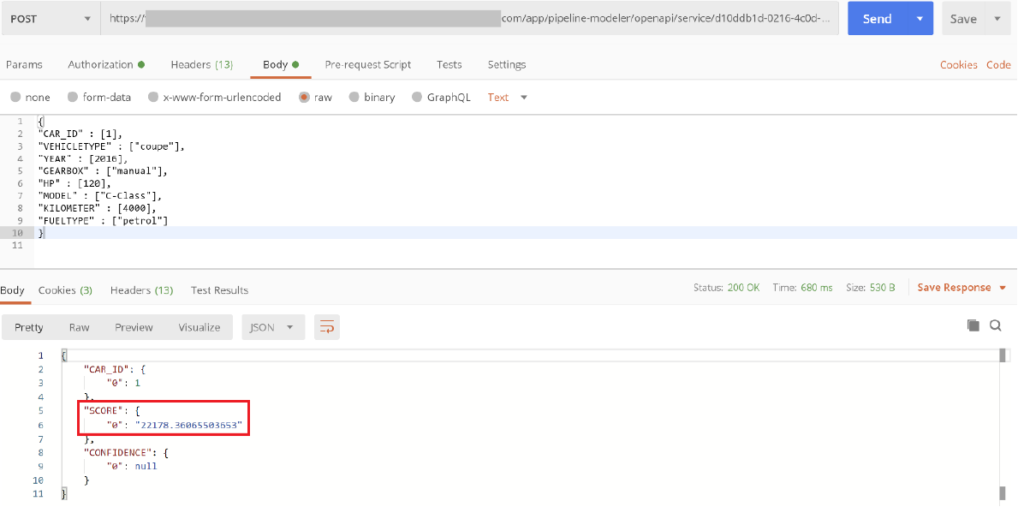
Uz kreirani najjači model, on sada može biti dostupan u potrošačkom kanalu putem RESTful API-ja, kao što je prikazano na snimci zaslona u nastavku.
Poziv RESTful API-ja za predviđanje cijena na bazi Machine Learning Model-a
Integracija Machine Learning Pipelines-a u Vaš IT sistemski pejzaž
Kako se Machine Learnig Pipeline s grafičkim korisničkim sučeljem može stvoriti i potpuno integrirati u krajolik Vašeg SAP sustava? U ovom postu na blogu pokazao sam vam kako je to moguće uz SAP Data Intelligence.
Nadalje, korištenjem Jupyter Notebook-ova s Pythonom, vrlo je jednostavno iterativni pristup kod Data Mining ili Data Science implementirati na integrirani način i jednostavno ih integrirati u postojeće poslovne procese i IT procese, čime se nudi dodana vrijednost.
Moje kolege i ja rado ćemo s Vama razmijeniti ideje o Vašim Data Science projektima i provjerit ćemo u kojoj Vam mjeri možemo pružiti podršku u budućnosti.
Dogovorite sada svoj Expert Call. Drago nam je zbog Vaše poruke.
