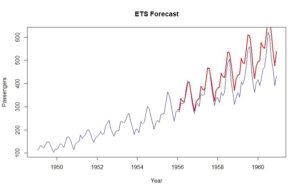
- Es ist nicht möglich, alle Daten in die SAP HANA zu laden. Die Datenmengen sind einfach zu gross, die HANA-Hardware für diesen Fall unverhältnismässig teuer. Es empfiehlt sich für die Masse an Rohdaten eine entsprechend skalierbare und kostengünstige Lösung zu verwenden, z.B. ein Apache Hadoop-Cluster. Solche Cluster bieten Skalierbarkeit über eine grosse Masse an günstiger Hardware und rechnen bereits in ihrer Architektur mit dem ständigen Ausfall einzelner Teile. So speichert das Hadoop-Filesystem HDFS die Daten immer mehrfach und ist daher betriebsbereit selbst wenn einzelne Server ausfallen. Gleichzeitig muss das System natürlich berücksichtigen, dass es die Mehrfach gespeicherten Daten nicht mehrfach zählt oder liefert. Dazu ist Hadoop entworfen worden. Von diesen grossen Datenmengen auf der Hadoop-Seite können nun kleinere Extrakte oder Aggregate durchaus in die HANA geladen werden, oder schon auf der Hadoop-Seite in-Memory vorgehalten werden, z.B. mit Hilfe des Spark-Adapters, wie sie auch in SAP Vora verwendet werden.
- Nicht nur Daten, sondern auch Ereignisse müssen orchestriert werden. Das Auftreten bestimmter Ereignisse in den Daten (z.B. Alarmmeldungen) kann sowohl auf der Big Data-Seite, dem Hadoop-Cluster, als auch auf der BW-Seite gewisse Prozesse triggern (Nachladen von Daten, Erstellen von Servicemeldungen, usw.). Diese Ereignisse müssen auf beiden Seiten jeweils orchestriert werden, damit Prozesse technologieübergreifend definiert werden können. Der SAP Data Hub bietet neben der Verwaltung der Datentransfers eben solch auch eine gemeinsame Verwaltung von Ereignissen, Jobs oder Triggern an.
Die einzelnen Bereiche werden separat gesteuert, aber ein kompletter Kreislauf kann so aussehen: ein Gut wird aus dem Hochregal entnommen, der zentrale Kran bringt es zum Brennofen, dort wird es (symbolisch durch blitzende Lichter) bearbeitet. Aus dem Brennofen kommt es zur Sortieranlage, eine Fotozelle erkennt die Farbe und entsprechend wird es in eines von drei Rutschen einsortiert. Von dort wird es wieder vom Kran entnommen und zum Hochregal gebracht, wo es wieder einsortiert wird. Die einzelnen Bereiche verfügen zum Teil über Sensoren wie Lichtschranken oder Fotozelle zur Farberkennung und über Motoren.
Hier der Link zur Produkthomepage dieser Fabrik: https://www.fischertechnik.de/de-de/service/elearning/simulieren/fabrik-simulation-24v .
Die Fabrik wird bereits komplett montiert geliefert, allerdings ohne Steuergeräte und demzufolge auch ohne entsprechende Programmierung. Um die Fabrik zu steuern, wurden acht Siemens Logo 8 Steuergeräte an die entsprechenden Sensoren und Motoren angeschlossen. Die Steuerung in der Logo-Sprache wurde dann von unserem Basis-Experten, Peter Straub, vorgenommen. Diese Programmierung ist recht aufwändig, die zur Verfügung gestellten Bestandteile von Sprache und Fabrik sind sehr einfach gehalten. Es gibt wenige Sensoren. Soll z.B. der zentrale Kran in Grundstellung gedreht werden, so wird er einfach eine bestimmte Zeit in eine bestimmte Richtung gedreht. Da er nicht über einen festmontierten Anschlag hinausdrehen kann, ist er damit in 0-Stellung. Die Bestandteile der LOGO-Sprache sind ebenfalls sehr elementar (UND-Gatter, ODER-Gatter, Zeitverzögerung und ähnliches). Es gibt z.B. keine komfortablen Variablen, die man z.B. für die Lagerhaltung nutzen könnte. Für die Verdrahtung der Geräte und der Programmierung der Fabrik kamen dann doch in etwa vier Wochen Aufwand zusammen.
Im nächsten Teil des Blog geht es dann darum, wie nun Daten aus dieser Fabrik in ein Big Data-Cluster kommen.